متدهای به کار گیری الگوریتم ژنتیک در پیشبینی لینک(قسمت سوم)
با استفاده از مدل 2، میتوانیم شبکهی در شکل 2B را به دو اجتماع بخشبندی کنیم و لینک (2، 1) هم متعلق به دو اجتماع است.

شکل 2: اجتماعات لینک سه شبکهی مجازی: (A) شبکه از 5 اجتماع مشترک تشکیل شده است. گرههای 1، 7، 12، 16 گرههای مشترک هستند. (B) شبکه شامل 2 اجتماع مشترک میشود، گرههای 1 و 2 گرههای مشترک هستند که به دو اجتماع متعلق دارند و لینک (2، 1) نیز متعلق به دو اجتماع است.
(C) شبکه از دو دستهی مشترک تشکیل شده است و سابگراف مشترک یک دستهی 3 تایی است.

در این شبکه، اجتماع سیستم بسکتبال از دو بخش تشکیل شده است. اعضای یک بخش از اجتماع جوانتر هستند و اعضای گروه دیگر از اجتماع مُسنتر هستند. به عبارت دیگر، گروه تیم بستکتبال، کاملاً به دو گروه دیگر ردهبندی شدند. با استفاده از مدل 2 میتوانیم شبکه را به سه اجتماع مشترک بخشبندی کنیم و روابط چندگانهی بین اجتماع تیم بسکتبال را به درستی تشخیص دهیم. مدل 2 میتواند برای بخشبندی شبکههای پراکنده (مثلاً شبکههای درختی) یا حتی شبکههای جدا از هم مورد استفاده قرار گیرد. مقدار تابع عینی بین 0 و 1 است. قبل از استفاده از مدل 2 برای بخشبندی یک شبکه، باید تعداد اجتماعات را داشته باشیم. اگر تعداد اجتماعات نامشخص است میتوانیم برای تشخیص آن از مدل 1 استفاده کنیم. میتوانیم تراکم ماکسیسم بخش را برای هر تعداد اجتماع داده شده بیابیم و سپس تمام تراکمهای بخش را برای یافتن تراکم ماکسیسم مقایسه کنیم. تعداد اجتماعات با تراکم ماکسیسم بخش تعداد نهایی اجتماعات است.
الگوریتم ژنتیک برای اکتشافات اجتماع لینک ما میتوانیم مدل 2 را با استفاده از نرمافزار لینگو برای بخشبندی شبکههای با مقیاس کوچک تقسیم آنها به اجتماعهای لینک استفاده کنیم، اما نمیتوانیم مدل برنامهریزی عدد صحیح را برای شبکههای با مقیاس بزرگ به کار ببریم که یک مشکل ناشی از چندجملهای غیرقطعی سخت است. به علاوه، اکثر الگوریتمها برای تشخیص اجتماع باید دانش اولیهای درباره ساختار اجتماع مانند تعداد اجتماعات داشته باشند که دانستن آن در شبکههای دنیای واقعی غیرممکن است. در ادامه، ما الگوریتم ژنتیک را برای کشف اجتماع لینک طراحی میکنیم. الگوریتم ژنتیک (GA) که یک روش بهینهسازی جهانی در هوش مصنوعی است. زمانی که فضای حل مسئله، برای اجازهدهی به جستجوی جامع برای راهحلهای بهینه و دقیق، بیش از حد
بزرگ باشد، الگوریتم ژنتیک میتواند مسئله را به یک فضای حل کوچکتر و مرتبط تغییر دهد و تقریباً راهحلهای بهینهای را ایجاد کند. نویسندگان، الگوریتمهای ژنتیک را برای حل مسئله کشف اجتماع گره در شبکههای یک عضوی یا دو عضوی طراحی کردند .در این مبحث ما الگوریتم کشف اجتماع لینک را براساس ایدههای ترکیبی الگوریتم ژنتیک و الگوریتم نقشهبرداری خودسازمانده ارائه کردیم که هدف آن یافتن بهترین ساختار اجتماع لینک توسط به حداکثر رساندن تراکم بخش لینک میباشد. این الگوریتم به هیچ دانش اولیهای دربارهی تعداد اجتماعات نیاز ندارد که باعث میشود این الگوریتم در شبکههای دنیای واقعی مفید باشد. خروجی الگوریتم ساختار نهایی اجتماع لینک و گرههای مشترک مربوط به آن به عنوان نتیجه است و پردازش بیشتری را بر خروجی تحمیل نمیکند.

معادلهی 13 برای هنجارسازی استحکامات عضویت میباشد بنابراین مجموع قدرت یک لینک متعلق به تمام اجتماعات مساوی 1 است. برای هر کروموزوم، یک ماتریکس بخشبندی D=(dj,c) را طراحی کردهایم که در آن j=1, 2, …, M و C=1,2,…,k است. هر عامل dj,c یا 0 یا 1 است.
Discovering Link Communities in Complex Networks by an Integer Programming Model and a Genetic Algorithm
2013
Zhenping LiXiang-Sun ZhangRui-Sheng WangHongwei LiuShihua Zhang
متدهای به کار گیری الگوریتم ژنتیک در پیشبینی لینک(قسمت دوم)
باتوجه به مثالی که در پست قبل آورده شد،برای شبکهی در شکل 2A میتوانیم آن را به 5 اجتماع مشترک {5، 4، 3، 2، 1} ، {11، 10، 9، 8، 7}، {15، 14، 13، 12} ، {18، 17، 16} ، {16، 12، 17} بخشبندی کنیم. و هر اجتماع یک دسته است. گرههای 16 ، 12، 7، 1 است. ما میتوانیم شبکهی در شکل 2B را به دو اجتماع که هر کدام یک دسته هستند بخشبندی کنیم. گره 1 و گره 2 به دو اجتماع تعلق دارند و لینک (2، 1) به اجتماع بزرگتر تعلق دارد. مقدار تابع عینی کمتر از 1 میباشد زیرا عضویت لینک (2، 1) در اجتماع منحصر به فرد است.

شکل 1. سه نتیجهی بخشبندی مختلف یک شبکهی درختی. (A) بخشبندی درست، (B,C) دو بخشبندی غیرشهودی. لینکهای
قرمز و گرههای مجاور، یک اجتماع را تشکیل میدهند، لینکهای آبی و گرههای مجاورشان، اجتماع دیگری را به وجود میآورند. گره
مشکی مشترک است. در مدل 1، از آنجا که هر لینک میتواند به فقط و فقط یک اجتماع تعلق داشته باشد، ممکن است به این نتیجه
برسیم که یک جفت گره به دو اجتماع تعلق دارند اما لینک بین آنها فقط به یکی از اجتماعات تعلق دارد. برای مثال، در شکل 2B، لینک (2، 1) فقط به اجتماع بزرگتر متعلق است. در واقع، گره 1 و گره 2 ممکن است دو رابطهی متفاوت داشته باشند مثلاً، آنها میتوانند در یک زمان، هم همکلاسی و هم خواهر باشند. بنابراین لینک (2، 1) باید هم به اجتماع همکلاسیها و هم اجتماع خانوادگی تعلق داشته باشد. به منظور رفع این اشکال، میتوانیم مدل 1 را اصلاح کنیم و به مدل زیر یعنی مدل 2 برسیم:

در مدل 2، قید 8 به این معناست که هر لینک باید به حداقل یک اجتماع تعلق داشته باشد. لینک متعلق به بیش از یک اجتماع به عنوان چندین لینک در تابع عینی (7) در نظر گرفته میشود.
Discovering Link Communities in Complex Networks by an Integer Programming Model and a Genetic Algorithm
2013
Zhenping LiXiang-Sun ZhangRui-Sheng WangHongwei LiuShihua Zhang
متدهای به کار گیری الگوریتم ژنتیک در پیشبینی لینک
تراکم قسمتبندی اجتماع لینک: اگر یک شبکه با M لینک و N گره داشته باشیم P={P1, … , PC}، قسمتی از لینکهای درون زیرمجموعه است. تعداد لینکها در اجتماع Ps، ms=|Ps| است. تعداد گرههای ایجاد شده از اجتماع Ps، است. تراکم جدید لینک Hs از اجتماع Ps به صورت زیر تعریف میشود:
![]()
![]()
میتوانیم ببینیم که مقدار ماکسیمم H، 1 و مقدار مینیمم آن 0 است. زمانی که هر اجتماع یک دسته باشد H=1 و زمانی که هر اجتماع یک گراف خالی باشد H=0 است. با داشتن تعداد اجتماعات، میتوانیم قسمتبندی بهینهی اجتماع لینک را با به حداکثر رساندن مقدار H پیدا کنیم. برای شبکهی در شکل 1، بخش O در شکل 1A مقدار حداکثر H را دارد. بنابراین میتوانیم به آسانی قسمتبندی بهینه را با به حداکثر رساندن H بیابیم.
مدل برنامهنویسی عدد صحیح برای قسمتبندی اجتماع لینک، اگر یک شبکهی G=(V,E) با M لینک و N گره داشته باشیم. میتوانیم فرض کنیم که تعداد اجتماعات لینک K میباشد و قسمتبندی اجتماع لینک بهینه را با به حداکثر رساندن تراکم H بیابیم. این مسئله میتواند به درون یک مدل برنامهنویسی عدد صحیح فرمولبندی شود. فرض کنیم که V={V1, V2, … , VN}، مجموعهی گرههای G باشد و E={e1 , e2 , … , em} مجموعهی کنارهی G باشد. ما R=(rij)N×M را به گونهای تعریف میکنیم که ماتریکس برخورد شبکهی G باشد که در آن rij=1 است اگر لینک ej با گره Vi برخورد کند و در غیر این صورت rij=0 است. ما همچنین متغیرهای دو دویی xjs و yis را برای نشان دادن عضویت لینک ej و گره Vi در اجتماع لینک Ps تعریف میکنیم.


مسئلهی بخشبندی اجتماع لینک میتواند از طریق مدل برنامهنویسی عدد صحیح زیر، مدل 1 فرمولبندی شود.

تابع عینی (1) برای به حداکثر رساندن تراکم بخشبندی لینک جدید H است.
قید (2) به این معناست که هر لینک به یک اجتماع تعلق دارد.
قید (3) بیان میکند که اگر یک یا بیشتر لینک در اجتماع Ps وجود داشته باشد که با گره Vi برخورد داشته باشند، بنابراین گره Vi باید به اجتماع Ps تعلق داشته باشد.
قید (4) بیان میکند که اگر گره Vi به اجتماع Ps تعلق داشته باشد، بنابراین حداقل یک لینک متلاقی با گره Vi وجود دارد که متعلق به اجتماع φs میباشد.
Discovering Link Communities in Complex Networks by an Integer Programming Model and a Genetic Algorithm
2013
Zhenping LiXiang-Sun ZhangRui-Sheng WangHongwei LiuShihua Zhang
استفاده از الگوریتم ژنتیک در پیشبینی لینک
استفاده از الگوریتم ژنتیک در پیشبینی لینک
در گذشته نشان داده شده است که سیستمهای جالب بسیاری میتوانند به صورت شبکههای متشکل از گرهها و لینکها نمایش داده شوند مانند اینترنت، شبکههای اجتماعی و دوستانه، شبکههای غذا و شبکههای نقل قول.
موضوع مهمی که اکنون در حوزهی شبکهها مورد علاقه واقع شده است، ایدهی اجتماعات و کشف آنها بوده است. کشف اجتماعات در یک شبکه یک مسئله جهانی در بسیاری از رشتهها مانند جامعهشناسی، علوم کامپیوتر و زیستشناسی است. به طور معمول، دو نوع اجتماع وجود دارند که به ترتیب اجتماعات گره و اجتماعات لینک میباشند. یک اجتماع گره یک سابگراف فشرده است که توسط گرهها ایجاد میشوند که در آن گرهها به طور متراکم درون سابگراف به هم وصل شدهاند اما با گرههای بیرون از سابگراف به طور پراکنده متصل هستند. اکثر روشهای موجود برای کشف اجتماع، حد فاصلی از گرههای شبکه یعنی اجتماعات گره را پیدا میکنند. در این نوع از بخشبندی، هر گره فقط و فقط در یک اجتماع قرار دارد. یک اجتماع لینک، سابگراف متراکمی است که توسط مجموعهای از لینکها ایجاد میشود که در آن لینکهای بسیاری درون سابگراف وجود دارد اما لینکهای کمی سابگراف را به بقیه شبکه متصل میکند کشف اجتماعات لینک به روش بخشبندی به این معناست که حدفاصلی از لینکهای شبکه را پیدا کنیم. در این نوع قسمتبندی، هر لینک فقط و فقط در یک اجتماع قرار دارد اما یک گره میتواند به اجتماعات چندگانه تعلق داشته باشد که عضویت لینکهای واقع بر آن در اجتماع بستگی دارد.
کشف اجتماع در رشتههای مختلف کاربردهای فراوان و مهمی دارد. برای مثال در زیستشناسی، کشف اجتماع برای یافتن ماجولهای تابعی پروتئین و پیشبینی توابع پروتئینی به کار برده شده است. در جامعه شناسی، ساختار اجتماع، یک ویژگی جغرافیایی مهم در ملاحظهی مداخلات واکسیناسیون بیماریهای عفونی در شبکههای تماس و فهم انتشار ویروس در شبکههای اجتماعی است.
در حالیکه، اکثر مطالعات قبلی در مورد کشف اجتماع بر اجتماعات گره، تمرکز داشتهاند، برخی از مطالعات اخیر شروع به بررسی اجتماعات لینک و دستههایش کردهاند.
در برخی از شبکههای واقعی، اجتماعات لینک میتوانند بیش از اجتماعات گره، تمرکز داشتهاند، برخی از مطالعات اخیر شروع به بررسی اجتماعات لینک و دستههایش کردهاند.
در برخی از شبکههای واقعی، اجتماعات لینک میتوانند بیش از اجتماعات گره، قابل درک و آگاهی بخش باشند زیرا یک لینک بیشتر محتمل داشتن هویت واحد است. در حالیکه یک گره، اغلب به چنین گروه تعلق دارد. برای مثال، اکثر اشخاص در جامعه هویتهای چندگانه دارند مانند خانوادهها، دوستان، همکاران در حالیکه اتصال بین دو نفر، معمولاً برای یک دلیل نمایان وجود دارد. از زاویهی دید عملی میتوانیم به طور طبیعی اجتماعات گرهای مشترک را با استفاده از قسمتبندی لینکها در اجتماعات تشخیص دهیم. زیرا لینکهای متصل به یک گره میتواند به اجتماعات لینکی مختلف تعلق داشته باشد و در نتیجه، گره میتواند به چنین اجتماع لینک تخصیص داده شود.
در یک مطالعهی اخیر، نویسندگان، دانسیته (تراکم) لینک در یک اجتماع لینک و تراکم بخش را تعریف کردند، تا کیفیت یک بخش از اجتماع لینک را ارزیابی کنند. اگر یک شبکه با m لینک و n گره داشته باشیم، P= {P1, … , PC} قسمتی از لینکهای در زیر مجموعههای C است. تعداد لینکها در زیرمجموعهی ms=|Ps| , Ps است. تعداد گرههای ایجاد شده است. تراکم لینک Ds در اجتماع Ps به این صورت تعریف میشود:

تراکم قسمت D به عنوان میانگین Ds تعریف میشود. یعنی:

میتوانیم ببینیم که مقدار ماکسیمم D، عدد 1 است. اما میتواند مقادیر کمتر از 0 را داشته باشد. هنگامی که هر اجتماع یک دسته باشد. D=1 و زمانیکه هر اجتماع یک درخت باشد D=0 است. زمانیکه یک شبکه به صورت درختی است نمیتوان با به حداکثر رساندن D آن را به اجتماعات مناسب تقسیمبندی کرد. زیرا تعداد زیادی بخش بهینهی مختلف وجود دارند و هر قسمت تراکم بخش یکسان و D=0 را دارد. برای مثال، شبکهی در شکل 1 از دو اجتماع با یک گره مشترک تشکیل شده است و هر اجتماع یک نمودار ستارهای است. اگر بخواهیم شبکه را با به حداکثر رساندن D به دو اجتماع تقسیم کنیم. یافتن نتیجهی درست نشان داده شده در شکل (A) سخت خواهد بود زیرا بخشهای در شکل 1B و شکل 1C نیز D=0 دارند.
در بیشتر مطالعات دربارهی قسمتبندی اجتماع لینک، در لینک به یک و فقط یک اجتماع تعلق دارد. اما در شبکههای دنیای واقعی، یک اتصال ممکن است نشان دهندهی بیش از یک رابطه بین دو گره باشد. برای مثال، دو نفر از یک خانواده، در یک مؤسسهی یکسان همکار هستند. در نتیجه دو اجتماع ممکن است لینکهای مشترک نیز داشته باشند. نتایج کمی دربارهی چگونگی قسمتبندی یک شبکه به اجتماعات لینک با لینکهای مشترک وجود دارد.
در این مقاله، ما دوباره تراکم بخش را برای اجتماعات لینک تعریف میکنیم. و مسئلهی بخشبندی اجتماع لینک با مدلهای برنامهنویسی عدد صحیح را فرمولبندی میکنیم. سپس ما، یک الگوریتم تکوینی را برای حل مسئله تشخیصی اجتماع لینک طراحی کردیم و معتبرسازی آن را بر روی برخی از شبکههای مجازی و دنیای واقعی اجرا کردیم.
Discovering Link Communities in Complex Networks by an Integer Programming Model and a Genetic Algorithm
2013
Zhenping LiXiang-Sun ZhangRui-Sheng WangHongwei LiuShihua Zhang
http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0083739
متد Simrank
متد Simrank :
Simrank یک متد است برای رتبه بندی درجه شباهت اشیاء.این متد بر این اصل استوار است که اکر دو جسم به اشیاء مشابه مرتبط باشند آن دو جسم مشابه هستند.ما می توانیم از این اصل برای پیش بینی لینک استفاده کنیم. بدین صورت که بگوییم دو گره مشابه هستند اگر همسایه مشابه داشته باشند.بنابراین ، a و b مشابه هستند اگر متصل باشند c و d ،به شرطی که c و d خود مشابه باشند. اساس کر این است که شیء شبیه به خود باشد. به عنوان مثال a کاملا مشابه a است.
ما می توانیم شباهت را در مقیاس [0,1] اندازه گیری کنیم، هنگامی که 1 ماکزیمم شباهت باشد و 0 کاملا غیر مشابه باشد. یک گره که به هیچ یک از گره های دیگر متصل نیستند با دیگر گره های موجود در شبکه دارای شباهت 0 است.
به عنوان مثال چگونگی شباهت در یک حالت انتشار پایه در شکل زیر نشان داده شده است.این شکل یک شبکه بین چند دوست است.لسلی دارای بیشترین شباهت با خودش است ، بنابراین ما میتوانیم به این موضوع پی ببریم که آپریل و رون شاید با یکدیگر شباهت داشته باشند ،اما با میزان کمتر.به طور مشابه ، آپریل و رون مشابه هستند ، سپس ما میتوانیم استنباط کنیم که آنها با یکدیگر دوستان نسبی هستند، اندی و سپاستین نیز با یکدیگر مشابه هستند اما به میزان کمتر از آپریل و رون.البته این سری از شباهت به صورت n² جفت از افراد در شبکه گسترش میابد، و جفت های مشابه دیگر تحت تاثیر گره های بیرونی لسلی قرار می گیرند.
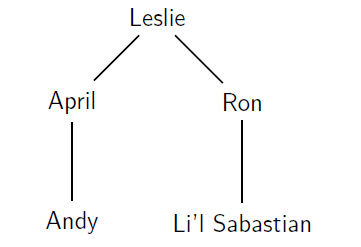
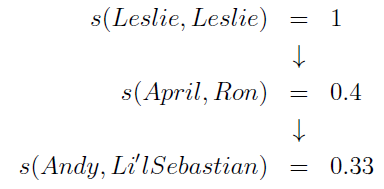
در شکل بالا نشان داده شده است که لسلی بیشترین شباهت را به خودش دارد s(Lesley,Lesley)=1 ،شباهت از دوستان او منتشر می شود همچنین از دوستان دوستان.
این ایده بر اساس شباهت هاست و بر اساس این نظریه که شباهت ها به شباهت های بین همسایگان بستگی دارد، که بستگی به شباهت های همسا یه ای که به صورت برگشتی به خود تعریف می شود.
برای اندازه گیری شباهت بین دو گره با اشاره به s(a,b) :
(1)
![]()
ما به گونه ای امتیاز بین دو گروه را برای هدف اکتشافی خود تعریف می کنیم که شباهت بین دو گره برابر باشد با:
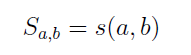
در معادله (1) مورد اصلی تعریف شده شباهت یک گره به خودش است، مورد بازگشتی تکرار همه جفت های همسایه (z,z´) از (a,b) است،خلاصه شباهت s(z,z´) بین هر یک از این جفت ها وجود دارد.سپس تقسیم بر تعداد کل جفت های همسایه می کنیم.
|Γ(a)||Γ(b)| ،برای نرمالسازی جمع انجام می شود. بنابراین ، این اساس معدل گیری شباهت های همسایه های a و همسایگان b است.باید توجه داشت که به معنای تقارن است یعنی s(a,b)=s(b,c)
ثابت c را می توان به عنوان یک فاکتور تعدیل یا فاکتور اعتماد در نظر گرفت.به عنوان مثال ،در مثال قبل از شکل 4 ،هنگامی که ما آپریل و رون را مشابه هم در نظر گرفتیم و در حقیقت لسلی با آنها دوست است ،در این حال ما میتوانیم بگوییم s(april,ron)=s(leslie,leslie)=1 ،اما چیزی که خیلی می توان از آن اطمینان داشت درجه شباهت بین آپریل و رون در این مدت است.
بنابراین بهتر است ما بوسیله یک ثابت شرایط را بهبود ببخشیم.بطوریکه:
s(april,ron)=c.s(leslie,leslie) برای c=[0,1] . ولی در حقیقت افراد اغلب از c=0.8 استفاده میکنند.
Anne Gatchell -Andy McEvoy CSL - Link Prediction Link Prediction in Social Networks
April 29, 2013