
متد Simrank
متد Simrank :
Simrank یک متد است برای رتبه بندی درجه شباهت اشیاء.این متد بر این اصل استوار است که اکر دو جسم به اشیاء مشابه مرتبط باشند آن دو جسم مشابه هستند.ما می توانیم از این اصل برای پیش بینی لینک استفاده کنیم. بدین صورت که بگوییم دو گره مشابه هستند اگر همسایه مشابه داشته باشند.بنابراین ، a و b مشابه هستند اگر متصل باشند c و d ،به شرطی که c و d خود مشابه باشند. اساس کر این است که شیء شبیه به خود باشد. به عنوان مثال a کاملا مشابه a است.
ما می توانیم شباهت را در مقیاس [0,1] اندازه گیری کنیم، هنگامی که 1 ماکزیمم شباهت باشد و 0 کاملا غیر مشابه باشد. یک گره که به هیچ یک از گره های دیگر متصل نیستند با دیگر گره های موجود در شبکه دارای شباهت 0 است.
به عنوان مثال چگونگی شباهت در یک حالت انتشار پایه در شکل زیر نشان داده شده است.این شکل یک شبکه بین چند دوست است.لسلی دارای بیشترین شباهت با خودش است ، بنابراین ما میتوانیم به این موضوع پی ببریم که آپریل و رون شاید با یکدیگر شباهت داشته باشند ،اما با میزان کمتر.به طور مشابه ، آپریل و رون مشابه هستند ، سپس ما میتوانیم استنباط کنیم که آنها با یکدیگر دوستان نسبی هستند، اندی و سپاستین نیز با یکدیگر مشابه هستند اما به میزان کمتر از آپریل و رون.البته این سری از شباهت به صورت n² جفت از افراد در شبکه گسترش میابد، و جفت های مشابه دیگر تحت تاثیر گره های بیرونی لسلی قرار می گیرند.
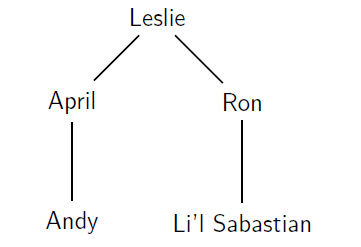
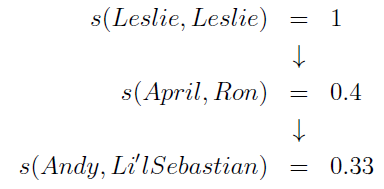
در شکل بالا نشان داده شده است که لسلی بیشترین شباهت را به خودش دارد s(Lesley,Lesley)=1 ،شباهت از دوستان او منتشر می شود همچنین از دوستان دوستان.
این ایده بر اساس شباهت هاست و بر اساس این نظریه که شباهت ها به شباهت های بین همسایگان بستگی دارد، که بستگی به شباهت های همسا یه ای که به صورت برگشتی به خود تعریف می شود.
برای اندازه گیری شباهت بین دو گره با اشاره به s(a,b) :
(1)
![]()
ما به گونه ای امتیاز بین دو گروه را برای هدف اکتشافی خود تعریف می کنیم که شباهت بین دو گره برابر باشد با:
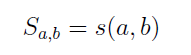
در معادله (1) مورد اصلی تعریف شده شباهت یک گره به خودش است، مورد بازگشتی تکرار همه جفت های همسایه (z,z´) از (a,b) است،خلاصه شباهت s(z,z´) بین هر یک از این جفت ها وجود دارد.سپس تقسیم بر تعداد کل جفت های همسایه می کنیم.
|Γ(a)||Γ(b)| ،برای نرمالسازی جمع انجام می شود. بنابراین ، این اساس معدل گیری شباهت های همسایه های a و همسایگان b است.باید توجه داشت که به معنای تقارن است یعنی s(a,b)=s(b,c)
ثابت c را می توان به عنوان یک فاکتور تعدیل یا فاکتور اعتماد در نظر گرفت.به عنوان مثال ،در مثال قبل از شکل 4 ،هنگامی که ما آپریل و رون را مشابه هم در نظر گرفتیم و در حقیقت لسلی با آنها دوست است ،در این حال ما میتوانیم بگوییم s(april,ron)=s(leslie,leslie)=1 ،اما چیزی که خیلی می توان از آن اطمینان داشت درجه شباهت بین آپریل و رون در این مدت است.
بنابراین بهتر است ما بوسیله یک ثابت شرایط را بهبود ببخشیم.بطوریکه:
s(april,ron)=c.s(leslie,leslie) برای c=[0,1] . ولی در حقیقت افراد اغلب از c=0.8 استفاده میکنند.
Anne Gatchell -Andy McEvoy CSL - Link Prediction Link Prediction in Social Networks
April 29, 2013
متد کاتز Katz
متد کاتز (katz):
میخواهیم به ایده جهان کوچک و ایده های موجود در همسایگان مشترک رویکرد دیگری داشته باشیم،اگر یک مسیر کوتاه بین دو گره نشان می دهد که ممکن است یک لینک مناسب بین آن دو وجود داشته باشد،بنابراین اگر تعدادزیادی مسیر کوتاه بین دو گره وجود داشته باشد احتمال قوی تری برای وجود ارتباط بین این دو گره وجود دارد.آزمایش بر روی گراف G´ در شکل زیر نشان داد که مسیرهایی بین شما و گره های B و C وجود دارد.
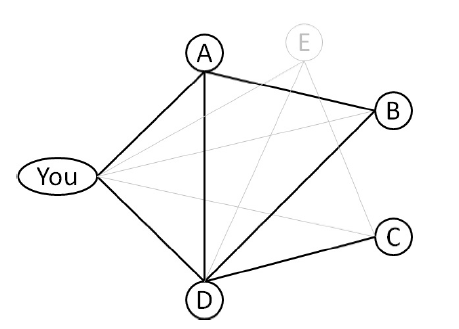
این مشاهدات در جدول زیر برای نمایش جزییات طول مسیرهای مختلف و همچنین نشان ارزش کمتر طول مسیرهای بلند تر نمایش داده
شده است :
|
طول مسیر |
فاصله های شما و گره B |
فاصله های شما و گره C |
تعدیل |
|
2 |
2 |
1 |
2/1 |
|
3 |
2 |
1 |
4/1 |
|
4 |
0 |
1 |
8/1 |
محاسبه امتیاز بر اساس همه مسیرهایی که بین شما و گره B و C در گراف G´ وجود دارد.
با استفاده از این جدول میتوانیم یک امتیازی را برای هر یال ممکن محاسبه کنیم که در دو معادله زیر نشان داده شده است:
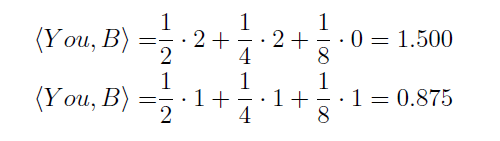
و اگر بخواهیم بطور رسمی تر عنوان کنیم،از تابع زیر استفاده می کنیم:
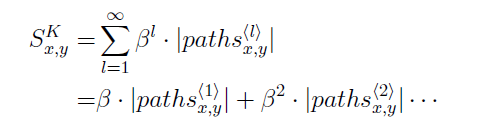
جاییکه β فاکتور وزن است و معمولا انتخاب به گونه ای انجام می شود که مسیرهای دیگر نمی توانند تحت تاثیر احتمال یک لینک بین
دو گره قرار گیرند.
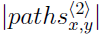 به معنای وزن همه مسیرهای بین x و y در طول L است .این متد می تواند برای استفاده از فرم
عمق اولین جستجو Depth
first search))
پیاده سازی شود.
به معنای وزن همه مسیرهای بین x و y در طول L است .این متد می تواند برای استفاده از فرم
عمق اولین جستجو Depth
first search))
پیاده سازی شود.
هر یال به عنوان یک درخت شناخته می شود،یال های عقب ،جلو و یا یال هایی که یکدیگر را قطع می کنند ،شما می توانید از این طریق تعداد مسیر هایی که به هر گره می رسد را بدست آورید و همچنین می توانید طول این مسیر ها را نیز بدست آورید.
Anne Gatchell -Andy McEvoy CSL - Link Prediction Link Prediction in Social Networks
April 29, 2013
متد همسایگان مشترک Common neighbors
متد همسایگان مشترک (Common neighbors) :
بسط و گسترش الگوریتم جهان کوچک ، این تصویر کلی را برای ما پدیدار می سازد که همسایگان بدون واسطه یک گره اطلاعات با ارزش درباره یال های احتمالی گره X را نگهداری می کنند، بنابراین x))Γ را به عنوان مجموعه ای از همسایگان گره x علامت گذاری میکنیم.
اگر مفهوم homophily در بحث خوشه بندی را مد نظر بگیریم ،منافع بین دو نفر ، نظیر x ,y همانند روابط دوستی بین دو آن دو نفر است.
اگر به این مقوله از منظر پیشبینی لینک نگاه کنیم ، اگر دو نفر به عنوان مثال x و y ، دوستان مشترک زیادی دارند ، احتمال بسیار زیاد وجود دارد که x و y نیز با هم دوست باشند.این مفهوم پایه و اساس متد همسایگان مشترک و پیشبینی لینک است.
با بررسی میزان همپوشانی دو گروه همسایه ، ما میتوانیم احتمال وجود لینک بین دو گروه را بررسی کنیم:
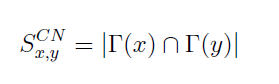
اگر نمودار G´ به عنوان یک لیست مجاورت ذخیره شده است ، به سادگی می تواند به عنوان یک لیست عملیات مقایسه بین هر یک از گره های لیست استفاده شود و می تواند o(n lg n) بارانجام شود چنانچه دو لیست ذخیره شده باشد،یا o(n) بار انجام شود اگر لیست ها حالت مخلوط داشته باشند.
با بررسی گراف شکل زیر میتوانیم ببینیم که شما همسایگان مشترک بیشتری با گره B دارید تا گره C ،بنابراین لینک بین شما و B با احتمال بیشتری پیشبینی می شود تا لینک بین شما و گره C .
Anne Gatchell -Andy McEvoy CSL - Link Prediction Link Prediction in Social Networks
April 29, 2013
https://www.cs.cornell.edu/home/kleinber/link-pred.pdf
متد کوتاهترین مسیر
متد کوتاهترین مسیر:
الگوریتم جهان کوچک را در نظر بگیرید . میلگرام در آزمایشی افراد مختلفی را از نبراسکا و کانزاس انتخاب کرد و برای آنها نامه ای فرستاد.در این نامه او از این افراد خواسته بود که در آزمایش او شرکت کنند.از آنها خواسته شد که نامه ای را به فرد خاص در بوستون بفرستند ،تنها با استفاده از افرادی که آنها را بر اساس نام کوچکشان می شناسند .هنگامی که میلگرام به نتایج نگاه کرد ،منوجه شد که هر کدام از افراد با حدود شش نفر تماس گرفته اند تا به هدف برسند ،به طور متوسط مردم ایالات متحده آمریکا توسط 6 نفر جدا می شوند(یا به عبارتی ارتباط بین دو نفر توسط 6 نفر برقرار می شود) که به آن قانون 6درجه جدایی (six degrees of separation) می گویند.
بنابراین در روش کوتاهترین مسیر ما به فاصله بین دو گره نگاه میکنیم و احتمال اینکه یک لینک به عنوان منفی کوتاهترین فاصله بین دو گروه باشد را تخمین میزنیم:
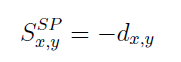
پیاده سازی اولیه این استراژی میتواند فضای جستجو را برای اولین بار و فرض اینکه هر گره به طور متوسط دارای n همسایه است،o(v´.nˡ) زمان پیش بینی بر آورد را بر روی گراف ورودی G´ انجام میشود.در مثال گراف G´ که در شکل زیر نمایش داده شده است،هم B و هم C در فاصله 2 از شما واقع شده اند ، به طوریکه می توانند با احتمال برابر پیشبینی شوند.
Anne Gatchell -Andy McEvoy CSL - Link Prediction Link Prediction in Social Networks
April 29, 2013